Why feature standardisation can improve classification results
In a previous post, we saw when and why feature normalisation before training a supervised classifier may needed. The main point of the post was about the fact that distance based classifiers need to operate on features which have similar dynamic ranges.
One thing we didn't discuss is why often things work better when the normalisation is done towards the [0-1] or the [-1,1] intervals rather than, for instance, the [0-100] range.
If you have used the SVM classifier, even with a linear kernel, using standardisation yields faster learning times and improved classification accuracy. Why is this the case?
SVM training usually uses optimisers (solvers) which are complex machines. Therefore, there may be several reasons for this behaviour, but one of them is the representation of floating point numbers in the computer. This representation is defined by an IEEE standard. In a nutshell, this representation gives different precisions to different ranges of values: the closer numbers are to 0, the higher the precision with which they are represented.
For a longer explanation, have a look at John Farrier's Demystifying Floating Point talk at CPPCon 2015. Farrier uses a visual example borrowed from an MSDN blog post that I am reproducing here:
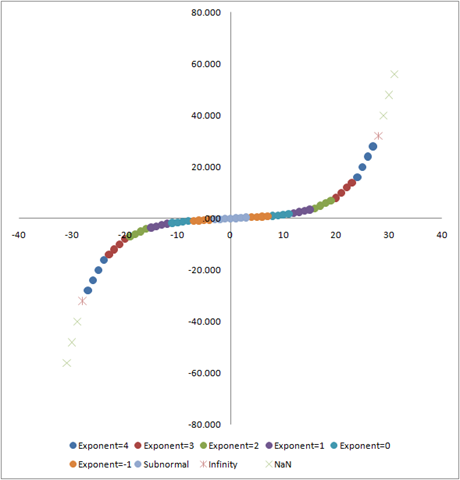
This plot means that the error with which a value is represented in the computer increases exponentially as a function of the value itself. It is therefore easy to understand that this representation error will make things difficult for optimisers even in the case where the cost function is quadratic, smooth and well conditioned.
Therefore, in order to make sure that the optimisation procedure benefits from accurate computations, rescaling feature values close to zero is useful.
Classification algorithms which do not optimise a cost function can also benefit from this rescaling. KNN classifiers, Self Organising Maps and many other algorithms using distances to select and sort will produce more accurate results.
On the other hand, if you use a tree-based classifier with a Gini purity index (like the Random Forest canonical implementation), rescaling is not needed, since the purity is computed over fractions which are already small numbers.
However, bear in mind that some tree-based classifiers use entropy (information gain) or other purity measures, like variance reduction which involve computations which may benefit from the increased precision obtained by the rescaling.
As a rule of thumb, in case of doubt, rescaling data will do no harm.
If you use the ORFEO Toolbox (and why wouldn't you?), the
TrainImagesClassifier and the ImageClassifier applications have
the option to provide a statistics file with the mean and standard
deviation of the features so they samples can be standardised. This
statistics file can be produced from your feature image by the
ComputeImagesStatistics application. You can therefore easily
compare the results with and without rescaling and decide what works
best in your case.
